오늘은 대규모 언어 모델(LLM) 이 사람들의 복잡한 지시를 더 잘 이해하고 수행하도록 만드는 방법을 다룬 흥미로운 논문, WizardLM을 소개해보려고 합니다. 우리가 ChatGPT 같은 모델을 쓰다 보면 이런 경험 있죠?
“이 모델… 말은 잘하는데, 내 요구를 정확히 이해한 건가…?”
이 문제의 핵심은 바로 Instruction Tuning(지시문 학습)입니다.
그
리고 WizardLM은 여기서 한 단계 더 나아가 “AI가 스스로 더 어려운 지시문을 만들어서 학습한다”는 아이디어를 제시합니다.
사실 이 논문은 2023년에 나온 꽤 오래된 논문인데요..! LLM을 공부하다 보면 자연스레 합성 데이터 생성에 대해 관심이 많아지고 이 논문은 그 합성 데이터 생성의 혁신을 불러일으킨 논문입니다.
1. Abstract
기존 LLM은 대규모 텍스트로 학습되었지만, 사람들의 복잡한 지시를 안정적으로 따르는 능력은 충분하지 않았습니다.
그래서 등장한 것이 Instruction Tuning —사람이 작성한 “지시문 + 답변” 데이터로 모델을 추가 학습시키는 방식이죠.
하지만 여기엔 큰 문제가 있습니다.
- 사람이 고품질 지시문을 만드는 데 시간과 비용이 너무 많이 든다
- 특히 복잡한 지시문은 더 만들기 어렵다
👉 그래서 WizardLM은 이런 질문을 던집니다.
“사람 대신, LLM이 스스로 점점 더 어려운 지시문을 만들어 학습하면 안 될까?”
이 아이디어를 구현한 방법이 바로 Evol-Instruct 입니다.
2. Introduction — 왜 ‘복잡한 지시’가 중요할까?
기존 instruction 데이터는 이런 특징이 있습니다.
- 비교적 단순한 요청
- 단일 작업 위주 (요약, 번역, 분류 등)
- 현실 세계에서 쓰이는 복합적인 요구를 충분히 반영하지 못함
하지만 실제 사용자 요청은 이런 식이죠:
“이 글을 요약해주고, 초등학생도 이해할 수 있게 바꿔서, 마지막에 핵심만 bullet point로 정리해줘.”
이건 단순 요역이 아니라 요약, 난이도 조절, 형식 변환이 한 번에 들어간 복합 지시입니다.
WizardLM은 바로 이런 복잡도 높은 instruction을 대량으로 만드는 방법에 집중합니다.
3. Method — Evol-Instruction란 무엇인가?
아래 그림부터 보시면, Evol-Instruction에 대해 감을 잡을 수 있을겁니다..!

감이 오시나요? Figure 1은 Evol-Instruct의 실행 예시로서 간단한 초기 지시문
1 + 1 = ?
에서 시작하여, 복잡한 지시문으로 업그레이드하거나 새로운 지시문을 생성하기 위해 In-depth Evolving or In-breadth Evolving을 무작위로 선택합니다.
- In-depth Evolving: 제약 조건 추가, 심화, 구체화, 추론 단계 증가, 입력 복잡화의 다섯 가지 유형의 연산을 포함하여 복잡한 데이터셋을 확보합니다.
- In-breadth Evolving: 주어진 지시문을 기반으로 완전히 새로운 지시문을 생성하는 방법으로 데이터셋의 다양성을 확보합니다.
이러한 진화 과정을 통해 생성된 데이터는 단순히 양만 늘어나는 것이 아니라, 다양한 난이도와 주제를 포괄하는 풍부하고 복잡한 지시 데이터셋을 만듭니다. 또한, 실패한 진화(Instruction Eliminator)를 걸러내는 과정을 통해 데이터의 품질을 유지합니다.
구체적인 과정은 아래 그림을 통해 확인할 수 있습니다:

이 과정은 크게 세 가지 핵심 단계로 구성됩니다.
각 단계는 LLM의 생성 능력과 미리 정의된 진화 전략을 활용해 instruction 데이터셋을 점점 더 풍부하게 만듭니다.
먼저 출발점부터 보겠습니다.
초기 데이터셋: D(0)
이는 사람이 만든 소량의 instruction 데이터 또는 기존 자동 생성 데이터(예: Alpaca의 seed instruction)로 구성됩니다.
수식으로 표현하면 다음과 같습니다.
D(0) = { (I(0)ₖ, R(0)ₖ) }
- I(0)ₖ : k번째 초기 지시문
- R(0)ₖ : 그 지시에 대한 응답
즉, 아주 기본적인 (지시, 응답) 쌍들의 집합이 시작점입니다.
1단계: Instruction Evolver — 지시문 진화
이 단계의 목표는 기존 지시문을 더 어렵거나 더 다양하게 바꾸는 것입니다.
① 데이터셋에서 지시문 선택
초기 데이터셋 D(0)에서 각 지시문 I(0)ₖ 를 하나씩 가져옵니다.
② 진화 전략 무작위 선택
각 지시문마다 두 가지 진화 방향 중 하나를 무작위로 선택합니다.
논문에서는 여러 프롬프트 템플릿 중 하나를 균등 확률로 선택합니다.
- In-depth Evolving (난이도 상승)
- In-breadth Evolving (다양성 확장)
🔬 In-depth Evolving (난이도 증가)
기존 instruction을 유지한 채 점점 더 복잡하게 만듭니다.
사용되는 진화 유형 예시:
- 제약 조건 추가
- 더 구체적인 상황 설정
- 여러 단계의 추론 요구
- 입력 정보 복잡화
- 설명 과정 요구
즉, “같은 문제를 더 어렵게” 만드는 방향입니다.
🌐 In-breadth Evolving (다양성 증가)
이번에는 기존 지시와 유사하지만, 완전히 새로운 주제/작업의 instruction을 생성합니다.
즉, 데이터셋이 특정 유형에 치우치지 않도록 주제와 작업 범위를 넓히는 역할을 합니다.
③ LLM에게 진화 요청
선택된 진화 전략에 맞는 프롬프트와 함께 기존 지시문 I(0)ₖ 를 LLM(논문에서는 ChatGPT API 사용)에게 전달합니다.
LLM은 이를 바탕으로 새로운 지시문 I(1)ₖ 를 생성합니다.
2단계: Response Generation — 답변 생성
이제 진화된 instruction I(1)ₖ 이 준비되었습니다.
이 지시문을 다시 LLM에 입력하여 해당 지시에 대한 응답 R(1)ₖ 를 생성합니다.
이 단계가 중요한 이유는,
사람이 정답을 작성하는 것이 아니라
LLM이 스스로 “문제 + 모범 답안”을 동시에 만드는 구조이기 때문입니다.
이렇게 해서 새로운 학습 데이터 쌍 (I(1)ₖ, R(1)ₖ) 이 만들어집니다.
🧹 3단계: Instruction Eliminator — 진화 실패 필터링
하지만 모든 진화가 성공적인 것은 아닙니다.
그래서 생성된 데이터는 자동 필터링 단계를 거칩니다.
❌ 진화 실패로 판단되는 경우
- 정보가 부족해 의미 있는 instruction이 되지 않은 경우
- 응답 생성이 사실상 불가능한 경우
- 의미 없는 텍스트가 생성된 경우
- 프롬프트 문장을 그대로 복사한 경우
이런 샘플은 “진화 실패”로 간주됩니다.
✅ 성공/실패에 따른 처리
- 성공한 경우
- → (I(1)ₖ, R(1)ₖ) 쌍을 유효한 데이터로 저장
- 실패한 경우
- → 데이터셋에 추가하지 않고, 필요 시 다음 라운드에서 다시 진화 시도 가능
논문에서는 성공한 instruction은 데이터 풀에 추가하고, 실패한 instruction은 다시 시도 대상으로 남겨둔다고 설명합니다.
다음 라운드로 반복 진화
이제 성공적으로 필터링된 데이터들로 새로운 데이터셋을 구성합니다.
D(1) = { (I(1)ₖ, R(1)ₖ) | 진화 성공한 샘플 }
그리고 이 D(1)을 다시 입력으로 사용해 1단계 → 2단계 → 3단계 과정을 반복합니다.
논문에서는 이 진화 과정을 여러 라운드(예: 4 epochs) 반복합니다.
즉,
D(0) → D(1) → D(2) → … → D(M)
형태로 instruction이 점점 더 복잡하고 다양해집니다.
최종 단계: Fine-tuning 데이터셋 구축
모든 진화 라운드가 끝나면,
- 모든 라운드의 성공 데이터 통합
- → D(0), D(1), …, D(M)을 하나의 큰 데이터셋으로 합침
- 셔플(무작위 섞기)
- → 학습 순서 편향 방지
- 필요 시 샘플링동일한 데이터 양(예: 70K 샘플)을 무작위로 추출해 사용
- 논문에서는 기존 모델(Vicuna 등)과 공정 비교를 위해
이 최종 데이터셋으로 LLM을 Instruction Tuning 하면 바로 WizardLM이 됩니다.
4. Experiments — 그래서 성능은 얼마나 좋아졌을까?
아무리 데이터 생성 방식이 멋져도, 결국 중요한건 “그래서 모델이 실제로 더 똑똑해졌는가?” 입니다.
논문에서는 WizardLM의 성능을 검증하기 위해 기존 오픈소스 모델들과 비교 실험을 진행합니다.
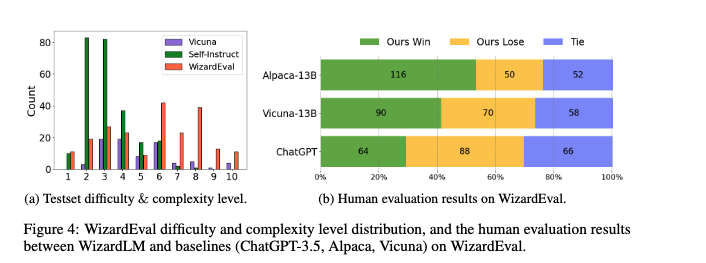
1) Human Evaluation (사람 평가)
사람 평가자는 두 모델의 답변을 보고 더 나은 쪽을 선택합니다.
평가 기준은 다음과 같습니다.
- 지시 이해 정확도
- 답변의 유용성
- 논리적 일관성
- 복잡한 요청 처리 능력
결과는 꽤 인상적입니다.
WizardLM은 기존 오픈소스 모델들보다 더 자주 선호되었고,
특히 복잡한 multi-step instruction에서 강점을 보였습니다.
즉, Evol-Instruct로 학습한 데이터가 정말로 “말귀 잘 알아듣는 능력”을 키워준 셈입니다.

2) Automatic Evaluation (자동 평가)
자동 평가에서는 모델이 다양한 지시를 얼마나 잘 수행하는지 테스트합니다.
여기서도 WizardLM은 다음과 같은 특징을 보였습니다.
✔ 단순 작업뿐 아니라 조건이 많은 복합 지시에서 강함
✔ 단계적 추론이 필요한 문제에서 성능 향상
✔ 형식 요구가 있는 출력(예: 표, 리스트 등)에서도 안정적
즉, 단순히 말 잘하는 모델이 아니라 “지시를 제대로 수행하는 모델”에 가까워졌다고 볼 수 있습니다.
흥미로운 관찰 포인트
이 논문에서 가장 인상적인 부분은 바로 이것입니다.
🧠 사람이 직접 만든 instruction 데이터보다 🤖 AI가 진화시켜 만든 instruction 데이터가 더 효과적이었다
이건 꽤 큰 메시지를 줍니다.
우리는 보통 “사람이 만든 데이터 = 고품질” 이라고 생각하지만, WizardLM은 “잘 설계된 AI 생성 데이터도 그에 못지않게 강력하다”는 걸 보여준 사례입니다.
5. Discussion — 이 연구가 중요한 이유
WizardLM의 기여는 단순히 모델 성능 개선이 아닙니다.
LLM 학습 방식 자체의 방향성을 바꿨다는 점이 핵심입니다.
기존 패러다임
사람이 데이터 만들고 → 모델이 학습
WizardLM이 보여준 새로운 방향
모델이 더 좋은 학습용 데이터를 만들고 → 그 데이터로 모델이 더 똑똑해짐
즉, 모델이 단순 소비자가 아니라 학습 데이터의 생산자 역할까지 하게 된 것입니다.
이 아이디어는 이후 등장한 많은 합성 데이터 기반 연구들에 직접적인 영향을 주었습니다.
6. Limitations — 그래도 한계는 있다
물론 이 방법이 완벽한 것은 아닙니다.
논문에서도 몇 가지 한계를 언급합니다.
- 생성된 instruction의 품질은 여전히 LLM 성능에 의존
- 잘못 설계된 프롬프트는 데이터 품질 저하로 이어질 수 있음
- 진화가 반복될수록 오류도 함께 증폭될 가능성
즉,
AI가 만든 데이터가 항상 정답은 아니다
라는 점은 여전히 중요합니다.
마무리 — WizardLM을 한 줄로 정리하면
WizardLM은 단순한 모델이 아니라,
“AI가 스스로 더 어려운 문제를 만들며 성장하는 학습 방식”
을 제시한 연구입니다.
이 논문 이후로 LLM 학습에서 합성 데이터(Synthetic Data)는 선택이 아니라 거의 필수 전략처럼 자리 잡게 되었습니다.
개인적으로 LLM 학습 공부를 하고 있는 입장에서 wizardLM을 쓴 것과 쓰지 않았을때의 실험을 진행해 볼 예정입니다.
이것도 많은 관심 부탁 드립니다. 감사합니다!!
