728x90
반응형
최근의 대규모 언어 모델(LLM)들은 단순히 원래의 Transformer 아키텍처를 그대로 쓰지 않습니다.
Original Transformer를 바탕으로 Normalization 위치, Attention 구조, Positional Encoding, FFN 활성화 함수 등 다양한 부분에서 수많은 변형이 이루어져 왔습니다.
저 역시 앞으로 LLM을 데이터 구축 → 사전학습(Pretraining) → 미세조정(Fine-tuning) → Post-training(RLHF 등) 전 과정까지 체계적으로 공부할 계획인데요.
그 시작점으로, 오늘은 LLM 구조의 한 축인 Feed-Forward Network(FFN) 안에서 최근 자주 쓰이는 활성화 함수 변형을 살펴보려 합니다.
특히 PaLM, LLaMA, Falcon 같은 최신 LLM들이 선택한 SwiGLU가 왜 단순 GeLU나 GLU보다 성능이 좋은지,
이 글에서는 GLU(Gated Linear Unit)와 SwiGLU를 비교하면서 그 차이와 장점을 정리해 보겠습니다.
1. 배경: Transformer의 FFN 구조
Transformer 블록의 FFN은 보통 다음과 같이 표현됩니다:

2. GLU (Gated Linear Unit)
정의:

3. SwiGLU (Swish-Gated Linear Unit)
정의:


4. 시각적 비교






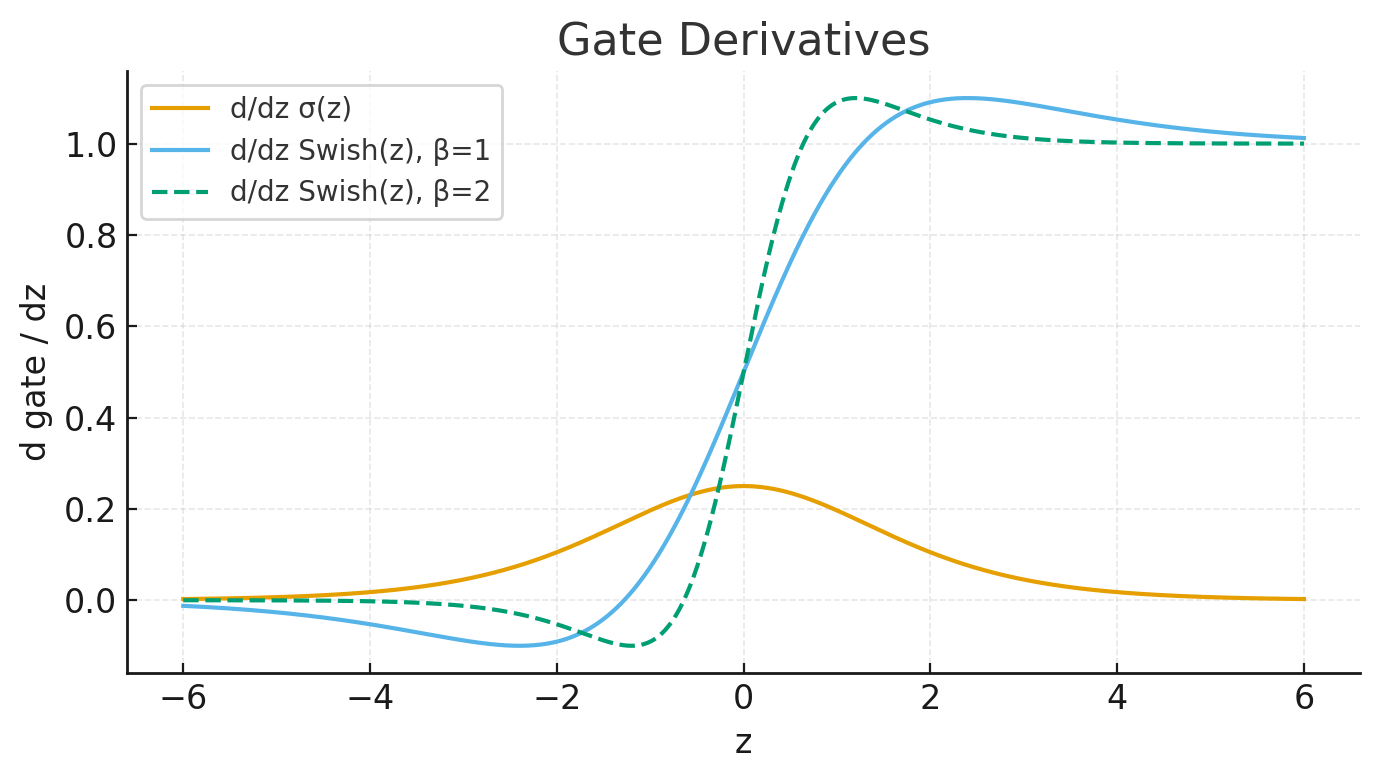
5. LLM에서의 채택 이유
- PaLM (Google, 2022): GeLU 대신 SwiGLU 사용 → 대규모 모델에서 성능 향상 확인.
- LLaMA (Meta, 2023): SwiGLU 채택 → 효율성과 성능 모두 개선.
- Falcon, MPT 등 최신 모델 다수도 SwiGLU를 선택.
장점 요약
- 표현력 증가: 게이트가 억제 + 증폭 모두 가능.
- 학습 안정성: gradient 흐름이 더 부드럽고 소실 위험 적음.
- 효율성: 같은 파라미터 예산 대비 성능이 더 좋음.
6. 결론
- GLU: “필터링(억제/통과)” 중심 → 단순한 feature selection
- SwiGLU: “필터링 + 증폭” → 정보 흐름을 더 풍부하게 제어
- 그래서 대규모 언어 모델에서는 GeLU → SwiGLU로 자연스럽게 넘어왔습니다.
앞으로도 롱컨텍스트, 더 큰 모델 최적화에서는 SwiGLU가 사실상 표준으로 자리잡을 가능성이 큽니다.
728x90
반응형
'AI > LLM' 카테고리의 다른 글
| ✋ RAG·Agent 글은 잠시 쉬어가고, 이제는 LLM 그 자체를 탐구하려 합니다 (0) | 2025.12.02 |
|---|---|
| FLOPs: 딥러닝 모델에서 왜 중요한가? (0) | 2025.09.19 |