본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다.
AI 분야로 취업하기 위해서는 LLM 관련 프로젝트를 경험해 보는 것이 거의 필수인 것 같습니다.
저는 2024년 8월에 인공지능 석사를 졸업하고, 12월까지 논문을 마친 후 2025년부터 본격적으로 취업 준비를 시작했습니다.
하지만, 취업 준비를 하면서 느낀 점이 있습니다.
당장 연구자로 취업하려면 박사 학위가 있어야 하고, 엔지니어로 취업하기 위해서는 RAG나 AI Agent를 실무에서 다뤄본 경험이 필요하다는 것이었습니다.
자연어처리(NLP) 연구를 했지만, RAG나 Agent에 대해서는 전혀 몰랐던 저는 솔직히 상실감에 빠졌습니다.

그래서 자연스럽게 강의를 찾게 되었고, 마침 이 강의를 발견했습니다. 그런데 운 좋게도 환급 챌린지를 진행하고 있어서 바로 신청했고, 4월 1일부터 강의를 시작하게 되었습니다.
현재 취업 준비 중이지만 매일 짧게라도 꾸준히 학습해나가려고 합니다!
오늘 수강한 내용은 RAG를 사용해야 하는 이유에 대한 내용입니다.
1. RAG (Retrieval-Augmented Generation) 란?- 검색, 증강, 생성
- 검색(Retrieval): 외부 지식 기반에서 관련 정보를 가져옵니다.
- 증강(Augmented): 검색된 정보를 기반으로 질문에 대한 맥락을 보완합니다.
- 생성(Generation): 보완된 정보를 바탕으로 자연스러운 답변을 생성합니다.
2. RAG를 사용해야 하는 이유
RAG 기술이 주목받고 있는 이유
먼저, 현재의 ChatGPT가 가질 수 있는 문제접에 대해 정리하면 다음과 같습니다.
- 최신 정보에 대해 학습되어 있지 않습니다.
- 나(개인) 혹은 우리 회사에 제한되어 있는 내부 데이터에 대한 학습이 되어 있지 않습니다.
- 따라서, 특정 도메인(나의 개인 정보, 회사의 내부 정보)에 대한 질문을 하면 기대하는 답변을 얻을 수 없습니다.
- 문서화시켜 업로드를 ChatGPT에서 질의할 수 있지만, 기대하는 답변을 받을 수 없거나, 할루시네이션(환각) 현상이 발생합니다. 게다가 문서의 양이 많아지면 더욱더 이러한 현상은 심해집니다.
그러나! 적합한 RAG를 적용했을 때는,
- 최신 정보를 기반으로 답변할 수 있으며, 정보를 찾을 수 없는 경우 “검색” 기능을 활용하여 답변할 수 있습니다.
- 나(개인)혹은 우리 회사에 제한되어 있는 내부 데이터를 참고하여 답변할 수 있습니다.
- 문서를 내부 DB에 저장할 수 있고, DB에 내용을 축적해 나갈 수 있으며, 저장된 DB에서 원하는 정보를 검색하여 검색된 정보를 바탕으로 답변할 수 있습니다.
- 답변에 대한 출처를 역으로 저장되어 있는 DB에서 검색 후 검증하는 방식으로 할루시네이션 현상을 줄일 수 있습니다.
궁극적으로 더 나은 답변 품질을 기대할 수 있으며, 방대한 지식 기반으로 답변하는 도메인 특화 챗봇을 생성하는 것이 가능합니다.
3. ChatGPT에 내장되어 있는 RAG?
ChatGPT에 문서를 업로드하여 질문을 하게 되면, 업로드된 문서를 기반으로 답변을 하게 됩니다.
하지만, ChatGPT는 RAG의 전반적인 과정을 블랙박스로 공개하고 있지 않기 때문에 어떠한 과정으로 RAG가 일어나는지 알 수 없습니다.
ChatGPT의 RAG과정은 공개되어 있지 않고, 우리가 컨트롤할 수 없는 부분이기 때문에 우리가 할 수 있는 유일한 최선은 ‘문서’를 ChatGPT가 잘 검색할 수 있는 형태로 변경하는 것입니다.
하지만, ChatGPT가 문서 검색을 잘 하도록 우리가 가지고 있는 문서의 형태를 모두 변경하는 것은 사실상 어려운 일입니다.
4. RAG 프로세스
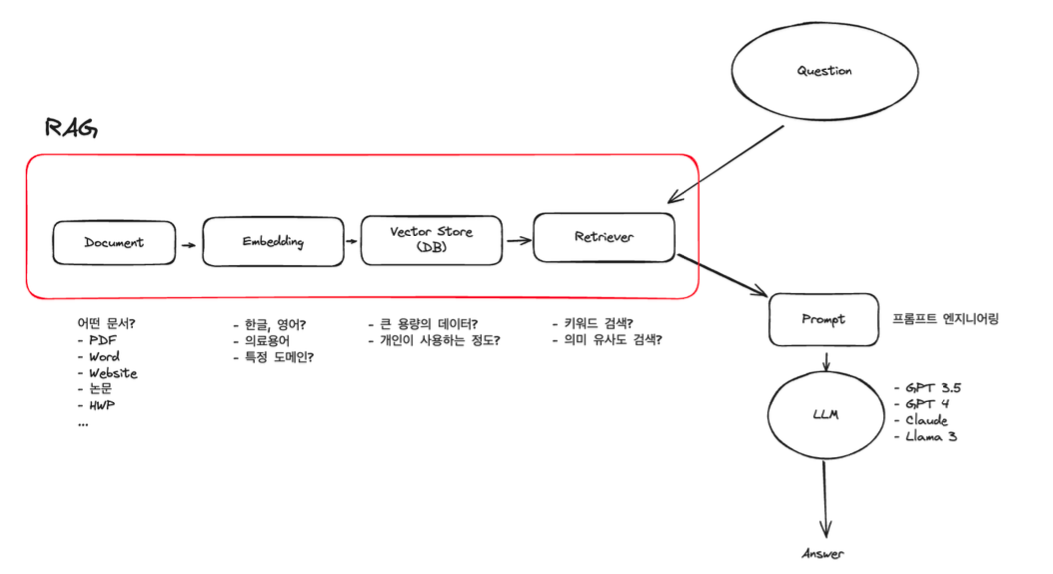
RAG의 기본적인 프로세스는 다음과 같이 구성됩니다:
- 질문 입력: 사용자의 질문이 입력됩니다.
- Retriever 단계: 벡터 DB에 저장된 문서들 중에서 질문과 가장 관련성 높은 문서를 검색합니다.
- Retrieved 문서 선택: 다수의 문서 중에서 상위 N개의 문서를 선택합니다.
- Generator 단계: 선택된 문서를 기반으로 LLM이 최종 답변을 생성합니다.
이 과정은 단순하지만 매우 강력하며, 검색 품질과 생성 품질 모두가 중요합니다.
따라서 각 단계에 다양한 기술을 적용하여 성능을 향상할 수 있습니다.
여기서 잠깐..! 벡터 DB가 뭘까요?
💡 벡터 DB(Vector Database)란?
1. 왜 필요한가요?
우리가 GPT나 다른 LLM에게 질문할 때,
그 질문과 관련된 문서를 잘 찾아서 답변의 기반으로 사용하게 하려면
문서의 내용을 단순히 '텍스트'로 저장하는 걸로는 부족합니다.
왜냐하면 LLM은 질문의 의미와 문서의 의미가 비슷한지를 숫자로 판단하기 때문이죠
이때 쓰이는 게 바로 벡터(Vector)입니다.
텍스트를 숫자로 바꾼 것 = 임베딩(Embedding) 벡터라고 생각하면 됩니다.
2. 벡터 DB는 뭐하는 건가요?
벡터 DB는 문서나 텍스트를 숫자(벡터)로 바꿔서 저장하고,
내가 질문을 하면 그 질문도 벡터로 바꿔서
문서들 중에서 가장 비슷한 의미를 가진 벡터를 찾아주는 DB입니다.
즉,
- 텍스트 → 숫자(벡터)로 바꿔 저장하고,
- 질문 → 숫자(벡터)로 바꾼 뒤,
- 의미적으로 가장 비슷한 문서를 찾아주는 DB!
이걸 가능하게 해주는 게 바로 벡터 DB입니다.
3. 예시로 쉽게 이해하기
예를 들어, 이런 문서가 저장되어 있다고 해봅시다:
- 문서 1: “AI는 인공지능을 의미합니다.”
- 문서 2: “강아지는 귀엽고 충성스럽습니다.”
내가 질문을:
“인공지능은 뭐야?”라고 하면
→ 이 질문을 벡터로 바꾸고
→ 문서1, 문서 2도 벡터로 변환돼 있으니
→ 문서1과 가장 비슷한 벡터라고 판단해서
→ 문서1을 찾아주는 거예요!
4. 대표적인 벡터 DB 종류
- Pinecone
- Weaviate
- FAISS (Facebook AI가 만든 오픈소스)
- Qdrant
- Milvus
요즘 RAG 프로젝트에서는 위 DB 중 하나를 선택해서 쓰는 경우가 많습니다.
🔑 요약
- 벡터 DB는 텍스트의 의미를 숫자로 바꿔 저장하고
- 의미적으로 비슷한 문서를 찾아주는 DB입니다.
- RAG에서는 질문에 맞는 문서를 찾기 위해 꼭 필요합니다!
5. RAG에 다양한 기법 적용 시 점진적 성능 향상

RAG의 성능은 다음과 같은 기법들을 적용함으로써 점진적으로 향상할 수 있습니다:
- Retrieval 개선
- Better embedding model (예: BGE, InstructorXL 등)
- Hybrid search (sparse + dense)
- Query rewriting (예: GPT 기반 재질문 생성)
- Context 구성 전략
- 문서 chunking 방식 개선 (Sliding window, semantic chunking 등)
- 문서 순위 정렬 기준 변경
- 불필요한 정보 제거로 context 정제
- Generation 개선
- Prompt engineering
- Chain-of-thought 유도
- Answer validation step 추가 (예: self-consistency)
- Feedback loop
- 유저 피드백 기반 성능 튜닝
- Retrieval 강화 학습 (RLAIF 등)
이처럼 RAG는 단순한 구조지만, 각 단계에 다양한 기술을 접목시킴으로써 정확도, 신뢰도, 사용자 만족도 모두를 향상시킬 수 있는 확장성 높은 기술입니다.
회고
오늘 이렇게 RAG가 무엇이고 왜 사용해야 하는지에 대해 알아보았습니다. 아직 한참 멀었지만 꾸준히 정진할 것입니다..!💪💪💪
이젠 인증샷 타임입니다.📷📷
- 공부 시작 인증
2. 공부 종료 인증
3. 클립 수강 인증

4. 학습 인증샷

모든지 꾸준히, 열심히, 성실히 가 최고라고 생각합니다. 끝까지 진행하도록 하겠습니다..!



